Note
0203-0217
z_e
2025. 2. 17. 11:24
*Cosine similarity를 임베딩 간 유사성 비교에 사용하는 이유
- 크기 차이 무시, 방향 비교
- Word2Vec, BERT, scRNA-seq ..등의 임베딩에서 코사인 유사도 사용해 벡터 간 의미적 유사성 비교
- 고차원 공간에서 euclidean distance 보다 더 신뢰가능.. 고차원 공간에서는 모든 벡터들이 서로 떨어지기 때문에 유클리디안 거리가 큰 의미가.. 그러나 코사인 유사도는 차원이 증가해도 상대적으로 더 일관된 유사성 제공
*Dot Product(내적) : 두 벡터의 방향, 크기를 모두 고려하여 유사성 측정
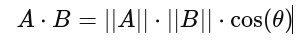
*squeeze(dim=0)은 첫 번째 차원(0번 차원)이 크기 1인 경우 제거
import torch
# 3D 텐서 생성
tensor = torch.rand(1, 3, 4) # shape: (1, 3, 4)
print(tensor.shape) # 출력: torch.Size([1, 3, 4])
# squeeze(0) 적용
squeezed_tensor = tensor.squeeze(0)
print(squeezed_tensor.shape) # 출력: torch.Size([3, 4])
tensor2 = torch.rand(2, 3, 4) # shape: (2, 3, 4)
squeezed_tensor2 = tensor2.squeeze(0)
print(squeezed_tensor2.shape) # 출력: torch.Size([2, 3, 4]) (변화 없음)
* 벡터 유사도 비교 시 정규화를 수행하여 unit vector를 사용. 방향성만 학습하게 만듬
L2 정규화는 벡터를 크기 1로 변환하는 것
Dot Product 값 == Cosine Similarity 값과 동일
*Early stopping
: 과적합(overfit)방지하기 위해, 검증 데이터의 성능을 모니터링하다가 손실이 개선되지 않는 상태가 일정 횟수(patient) 이상 지속되면 학습을 중단
os.path.splitext()
: 파일명과 확장자를 분리하는 함수, 모든 확장자(.txt, .csv, .h5ad 등)에 대해 범용적으로 동작
import os
file_names = [os.path.splitext(filename)[0] for filename in anndata_list]